- DeepSeekは、低価格なのに最新のChatGPTにも匹敵する性能を持つ、中国発のAIモデルです。
- 中国国内にデータを保存するDeepSeekアプリには、データプライバシーのリスクが存在する一方、言語モデルは既存サービスに組み込まれて始めています。
- DeepSeekのAIサービスと言語モデルは、区別して考える必要があります。
YouTube動画でも話しています
1. DeepSeekはゲームチェンジャー?
DeepSeekは、「低コストなのにChatGPTと同等の高性能を実現したAI」です。
6710億という膨大な量のパラメータを扱いながら、従来のAIと比べてコストを抑えながら、高い性能を発揮できます。
特にDeepSeek-R1モデルは数学的な計算や論理的推論が得意で、場合によってはOpenAIのOpenAIの最新AI「ChatGPT o1」を上回る性能を示すと報告されています。
DeepSeekは、まずDeepSeek社のクラウド上のAIサービスとして提供されています。
開発者は、APIを通じて自分のアプリケーションにDeepSeekの機能を組み込めます。
高性能でありながら利用料金は他のAIサービスと比べて格段に安価です。
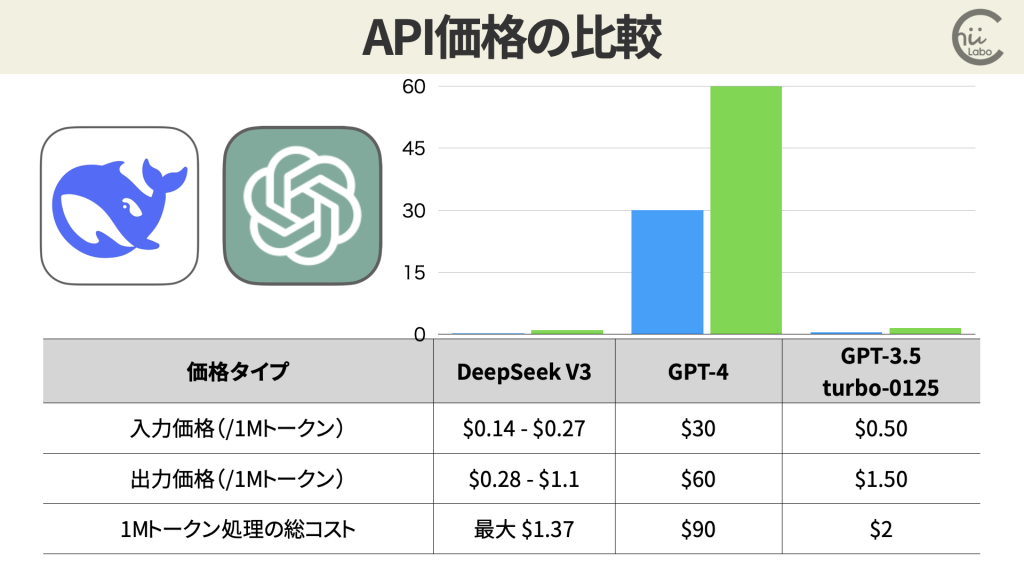
- DeepSeek V3は、GPT-4と比較して約1/10から1/100の価格で利用可能
APIを使うイメージは、アプリやウェブサイトを作る開発ソフトに組み込むのがわかりやすいです。
作っているコードをAI処理を通して変換できるようになります。
AIの開発コストを大きく下げる可能性を示した、重要な技術的ブレークスルーと言えます。
1.1. スタートアップとしてのDeepSeek
DeepSeekの特筆すべき点は、8億6000万円というAI開発にしては非常に低予算にもかかわらず、OpenAIの最新AIと同レベルの性能を持っている点です。
DeepSeek社は2023年、中国の杭州市で誕生した新興のAI企業です。
創業者の趙永剛(Zhao Yonggang)氏は、動画共有アプリTikTokで知られるByteDanceでAI研究者として活躍した人物です。
北京大学や清華大学という中国の名門大学を卒業した若手研究者たちが、開発チームの中核を担っています。
OpenAIは具体的な開発コストは公開していませんが、ChatGPTの運用コストだけで1日に約9,000万円(70万ドル)以上かかっている可能性があると報告されていて、開発コストはさらに膨大であったと考えられます。
1.2. 効率化のためのいろんな工夫
DeepSeekの革新性は、少ないメモリ使用量で精度の高い予測を高速に計算できることです。
全体としては、「学習」より「推論」にエネルギーを投下しています。
- 「MoE」は複数の専門AIモデル(エキスパート)を組み合わせて使う技術です。
各エキスパートが得意分野を担当し、タスクに応じて最適なエキスパートを選んで処理します。
この方式により、計算効率を高めながら高い性能を実現できます。 - AIが文章を生成する際、通常は1つずつ単語(トークン)を予測しますが、MTPは一度に複数の単語を予測します。
この技術により、処理速度が最大1.8倍に向上します。 - MLAはAIが文章を理解する際に使う技術です。
必要な情報に「注意を向ける」仕組み(Attention)を改良し、少ないメモリ使用量で効率的に情報を処理できます。 - AIの計算で使用する数値の精度を8ビットに抑えることで、メモリ使用量を削減し計算速度を向上させます。
必要な部分だけ高精度な計算を行うことで、性能を維持しながら効率化を実現します。
企業は以前より高性能のAIをコストを抑えながら導入できるようになります
1.3. GPU需要への影響(NVIDIAの株価)
DeepSeekは、「高価なNVIDIAのH100ではなく、より安価なH800を効率的に使う新しい学習方法を開発した」とされています。
この成果は、アメリカ企業が独占していたAI開発の常識を覆しました。
DeepSeekは従来の10分の1のコストでAIモデルを開発できることを示しました。
すると、高価なGPUを大量に購入するという従来のやり方は見直しを迫られることになります。
短期的に最も顕著な影響は、NVIDIAの株価の下落でした。
DeepSeekの発表により1日で17%下落しました。
NVIDIAが独占的な地位を築いていたAI向けGPU市場に、より安価な代替製品が台頭する可能性が出てきたためです。
ざっくり言うと、学習に特化したGPUから推論に特化したGPUに需要が移行する流れが、より鮮明になったことを意味しています。
加熱していた期待感が沈静化する材料になったようです。
他のハイテク企業にも波及し、ナスダック総合指数は3%以上下落しました。
AI開発の参入障壁を下がるため、ビックテック以外のより多くのスタートアップ企業がAI開発に参入して来ることが影響しているのかもしれません。
確かに、AIは GoogleやMeta、XやMicrosoftなどビックテックの存在感が大きいもんね。
これらの企業にとっては、脅威になるのかもね。
2. 【リスク】中国政府への情報漏洩やプライバシー侵害
DeepSeekの急速な成長には、中国政府の強力な支援が背景にあります。
米国による半導体の輸出規制という制約の中、中国国内で入手可能な部品で最高性能を実現するため、独自の最適化技術を開発しました。
ただし、中国発のAIであるため、データの取り扱いに関する懸念があることには注意が必要です。
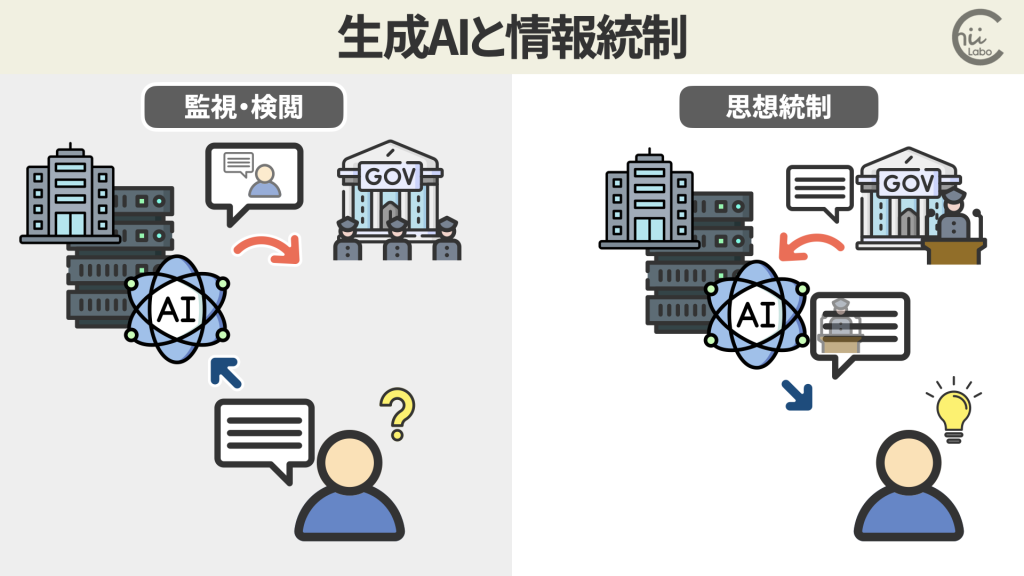
中国では国家情報法により、企業は中国政府の情報活動に協力する義務があり、DeepSeekも中国本土の法律に準拠すると規約に明記しているからです。
そのため、ユーザーがDeepSeekに入力データが中国のサーバーに保存され、政府による監視や利用の対象となる可能性があります。
このような中国政府への情報漏洩やプライバシー侵害への懸念から、アメリカの多くの企業や政府機関では、DeepSeekの使用を禁止するところも出ています1。
政府に「筒抜け」って、なんとなく嫌な気がするね。
2.1. AIは誰にとって「都合の良い」情報を出すのか?
DeepSeekは中国企業が開発したAIモデルであることは、中国政府の利益に沿った情報を優先的に提供するように調整されていることを意味します。
AIが生成する情報を「調整」すること自体は、これまでも一般的なことです。
例えば、犯罪や倫理的に問題のある生成はブロックされていました。
ただし、AIの回答する結果に、中国政府の見解や価値観が紛れ込んで来ることで、利用者の「常識」が変容・侵食されていくことのリスクも考える必要があります。
これは、SNSでの「情報の偏り」の問題と似ています。
大量の情報から見せるものを選別する「アルゴリズム」は、いわば「水道の水質管理」のようなものです。
米国でTikTokが槍玉に上がったのと同じ話かぁ。

3. 組み込まれ始めるDeepSeek
一方で、Microsoftは、中国発のAI技術「DeepSeek」を自社のクラウドサービスに組み込み始めています。
- 例えば、クラウドプラットフォーム「Azure AI Foundry」のモデルカタログに「DeepSeek-R1」が追加されました2。
- また、プログラマー向けの開発環境「Visual Studio Code」でも、DeepSeekの技術が使えるようになりました。
MicrosoftはDeepSeekを導入するにあたって、専門チームによる安全性の検証や、不適切なコンテンツを自動的にフィルタリングする仕組みを整えるなど「セキュリティ面での対策も万全を期している」としてます。
3.1. 言語モデルとして「DeepSeek」
ここで区別が必要なのは、
「DeepSeekは DeepSeek社のAIサービスだけではない」ことです。

2025年1月20日、DeepSeek社は「DeepSeek-R1-Zero」と「DeepSeek-R1」という2つの言語モデルを、自由に使えるMITライセンスで公開しました。
ユーザーは、GitHubやHugging Faceというプラットフォームからこれらのモデルをダウンロードし、自分のパソコンで動かしたり、カスタマイズしたりできます。
オープンソース版では、学習済みのモデルとその設定値(ウェイト)のみが公開されています。
つまり、オープンソース版のユーザーは、「完成品」を受け取って使用したり、新しい目的のために追加学習(ファインチューニング)させたりできますが、DeepSeekがどのようにしてこの高性能なモデルを作り上げたのかやAIの学習に使用したデータなどの核心部分は、非公開なのです。
「オープンソース」といっても、AIそのものの「設計図」が公開されている感じではないんだね。
3.2. 既存AIの「真似」?
DeepSeekの開発コストが極めて低いことは、一つの大きな疑惑を呼んでいます。
OpenAIは、「DeepSeekがGPT-4の出力を使用していた証拠がある」と主張しているのです3。
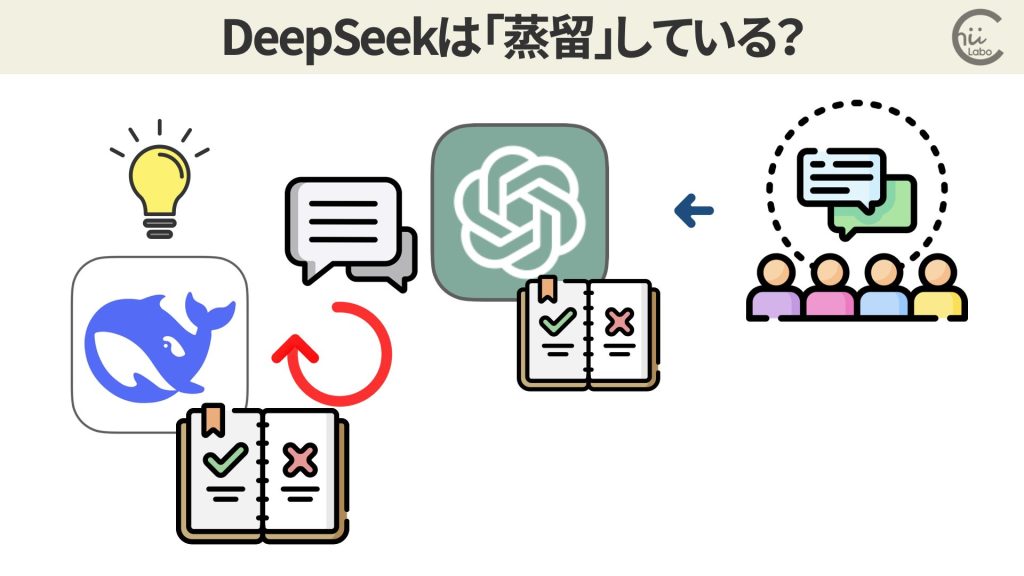
実際にDeepSeekの応答の中で、「Open AIの規約」に言及するなどGPT-4の特徴を示していることが指摘されています。
3.3. 「知識蒸留」という学習手法の是非
ただし、米国においても、スタートアップ企業や研究者がChatGPTなどの商用AIの出力を使って、新しいモデルを学習させること自体は珍しくないとされています4。
既存の大規模なAIモデル(教師モデル)の出力を使って、新しい小規模なモデル(生徒モデル)を学習させる手法は、「知識蒸留」(Knowledge Distillation)と呼ばれます。
開発コストを大幅に削減する手段として、業界では一般的な手法となっているのです。
この「蒸留」の使用を完全に証明したり、防止したりすることは技術的に難しい状況です。
生成AIそのものがクリエイターの培った技術から学習しているのに、自分が真似されるのは嫌なのかな?

(補足)
- 「ディープシーク」利用を制限 世界で数百、中国へ情報流出懸念 | 毎日新聞
- 【衝撃】DeepSeek R1がAzure AI FoundryとGitHubで利用可能に!エンタープライズAIの新時代 – trends
- DeepSeekがOpenAIのデータを「蒸留」してAIを開発していた可能性が浮上、OpenAIは「証拠がある」と発言 – GIGAZINE
- 「カリフォルニア大学バークレー校のAI博士候補であるリトウィック・グプタ氏は、「スタートアップや学者が、ChatGPTのような人間と連携した商用大規模言語モデル(LLM)の出力を使って別のモデルをトレーニングすることは、ごく一般的なことです」「DeepSeekが同じようなことをしていても、私は驚きません。もしそうだとしたら、この行為を正確に止めるのは難しいかもしれません」と語りました。」 DeepSeekがOpenAIのデータを「蒸留」してAIを開発していた可能性が浮上、OpenAIは「証拠がある」と発言 – GIGAZINE