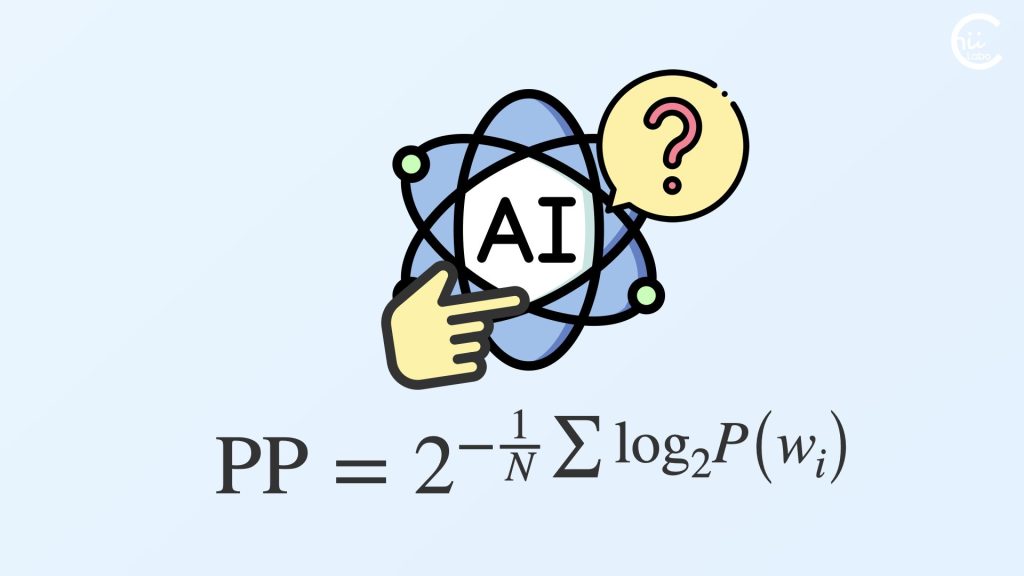
- Perplexityは言語モデルが次の単語を予測する際の確信度を示す指標です。
- Perplexity値が小さいほど予測精度が高く、大きいほどモデルがデータセットに対して困惑している状態を表します。
- 訓練データと検証データのPerplexity値を比較することで、モデルの学習状態や過学習の有無を確認できます。
1. ラテン語の「per-plexus」
もともと「Perplexity」は「困惑」という意味の言葉です1。
語源はラテン語の「perplexus」、「編み込まれた」「込み入った」に由来します。
- “per-“
(「完全に」「徹底的に」を意味する接頭辞) - “plexus”
(「編む」「織る」「絡ませる」を意味する動詞 plectere の過去分詞形)
二つが結合して「完全に編み込まれた」「複雑に絡み合った」という意味を形成しています。
AI研究の分野では、「Perplexity」は、言語モデルが次の単語を予測する際の確信度の逆指標2として使われています。
1.1. Perplexity値を計算する
Perplexity値(PP)は、次の単語を予測する際の確率分布のエントロピーの指数として計算します。
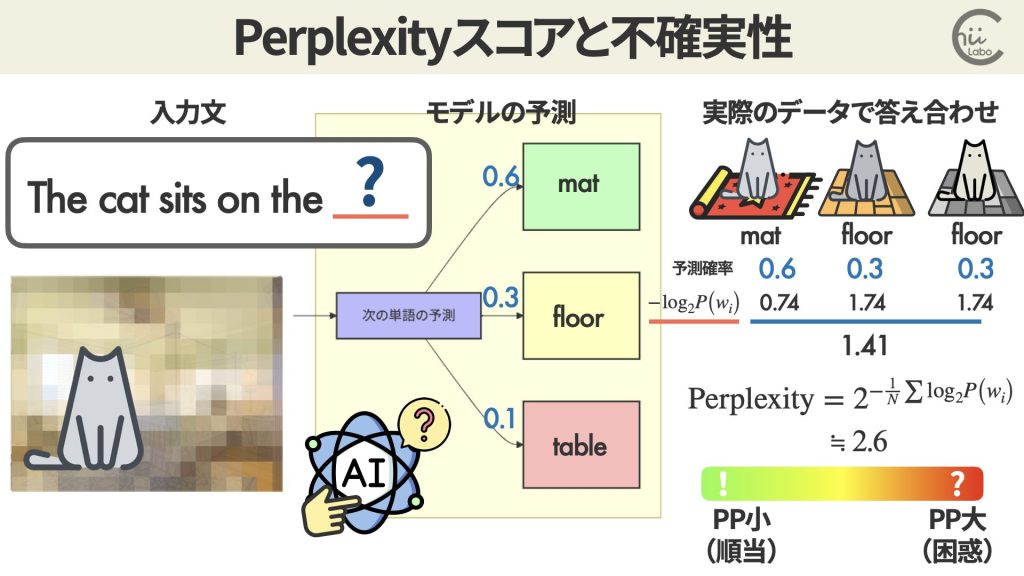
言語モデルにデータセットを与えて、それぞれ次の単語を予測させます。
実際の単語を予測した確率を元に Perplexity を計算し、データセット全体で平均化します。
- 各予測の確率を対数化
- それらの平均を取る
- 指数化してPerplexity値を得る
この値が小さければ、その言語モデルの予測精度が高いことになります。
例えば、ある言語モデルAが、mat 0.6, floor 0.3, table 0.1の確率だと予測しました。
実際に3個の検証データで答え合わせをすると、
- The cat sits on the mat.
- The cat sits on the floor.
- The cat sits on the floor.
という結果だったとします。
この場合のPerplexity値は、
Perplexity = 2^(- 1/3 (log2 0.6 + log2 0.3 + log2 0.3))
≒ 2^(1.41)
≒ 2.65
2. 言語モデルでのPerplexityの使われ方
Perplexityはトランスフォーマーベースの言語モデルの評価において、客観的で数値化された指標として重要な役割を果たしています。
つまり、異なる言語モデル間で性能を比較する際の指標としても使用できます。

別の言語モデルBが、mat 0.2, floor 0.6, table 0.2で予測するとすると、
Perplexity = 2^(- 1/3 (log2 0.2 + log2 0.6 + log2 0.6))
≒ 2^(1.27)
≒ 2.40
この例では、モデルB(2.40)< モデルA(2.65)
つまり、モデルBの方が良い予測ができていることを示しています。
実際のデータで”floor”が2回出現しているのに対し、モデルBがより高い確率(0.6)を割り当てていることに対応しています。
入力:「今日は良い」
モデル予測:「天気」の確率が0.7, 「日」の確率が0.2, その他0.1
データセットの実際の次の単語が「天気」だった場合、正解の単語の予測確率のみ(この場合「天気」の0.7)を使用します。
2.1. 言語モデルのトレーニング
Perplexityは、言語モデルのトレーニングの中でも利用されます。
モデルが訓練データセット全体を1周処理することを1エポックと呼びます。
例えば、10万文のデータセットを用意していたら、全て学習し終わると予測確率を集計します。
「学習」では、この予測精度を上げていくことが目標になります。
PP値が下がっていけば、モデルの学習が順調に進んでいることを示します。
また、訓練データと検証データで別々に Perplexityを計算することで、適切に学習できているか検証することもできます。
もし、訓練データでのPerplexityが低いのに、検証データでのPerplexityが高いなら、その差分は訓練時だけ有効な精度です。
つまり、「過学習」ということになります。
ただし、これは技術的な評価指標の一つであり、実際のアプリケーションにおける有用性は他の要因も考慮する必要があります。
3. 【補足】クロスエントロピーとPerplexity
Perplexityスコアで言語モデルの性能を比較できることはわかったけど、結局 これは何を計算しているの?
Perplexityは、クロスエントロピーHの指数関数として定義されています。
クロスエントロピーも、モデルの予測がどれだけ不確かさを含んでいるかを表します。
この値が小さいほど、モデルの予測は確実です。
Perplexityは、クロスエントロピーを2の指数にした値。
クロスエントロピーが「情報理論的な不確実さ」を表すのに対し、Perplexityは「平均的な分岐数」または「平均的な選択肢の数」として解釈できます。
3.1. 予測確率の逆数の幾何平均
Perplexityの式では、つまり、2の対数をいったん平均してから 2の指数にしています。
つまり、「各予測確率の逆数の幾何平均」として書き変えられます。
(∏は数学記号でpiと読み、掛け算の総和)
各予測確率の逆数とは、確率16.7% なら 6。
つまり、単純化すれば「各予測での選択肢の数」のことです。
もしモデルが常に正解の単語に確率1.0(100%)を割り当てられれば、Perplexity = 1。
これは「選択の余地がない=完璧な予測」を意味します
他方、Perplexity = 10 なら、これは「モデルが各予測ポイントで、平均して10個の選択肢の中から選んでいるような状態」を表します。
先ほどのモデルAの場合は、だいたい 2.65 個の選択肢から選んでいる(迷っている)状態だと言えます。
つまり、まさに「困惑度」なわけです。


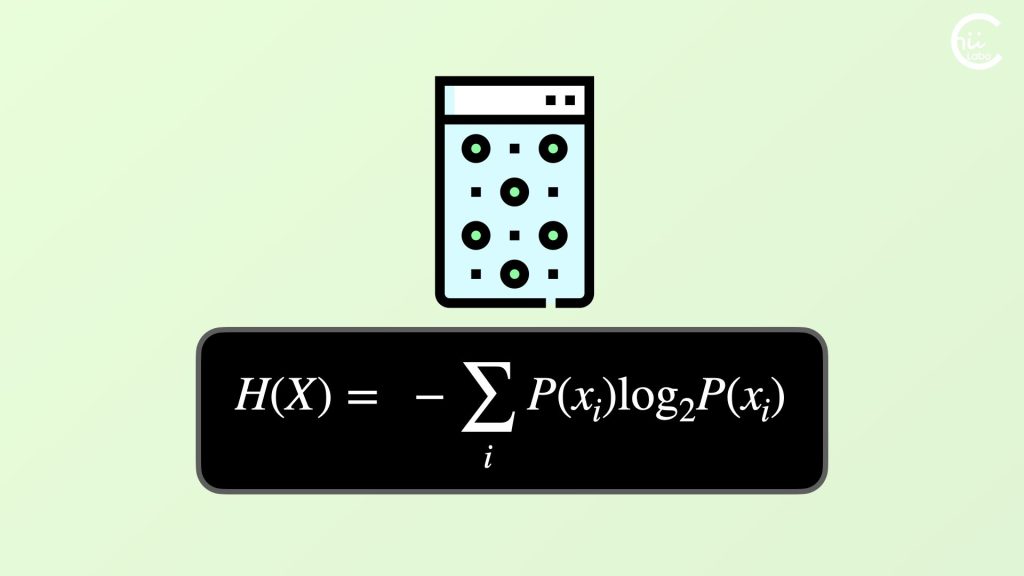


(補足)
- perplexity – Google 翻訳
- inverse metric
