![[PHP]ウェブページの内容を抽出するオンラインツールを作るには?](https://chiilabo.com/wp-content/uploads/2024/08/image-9-20240814-121740-1024x576.jpg)
- ウェブページから必要な記事を簡単に抽出するツールを作りました。
- 使い方は、URLを入力して「Extract Article」ボタンを押すだけで、記事内容が表示されます。
信頼できるソースのURLのみを使用し、個人利用や研究目的に限定してください。
1. ツールの使い方
インターネット上には膨大な情報があふれていて、必要な情報だけを見るのは大変な作業です。
そこで、ウェブページから記事を簡単に抽出できるツールを作りました。
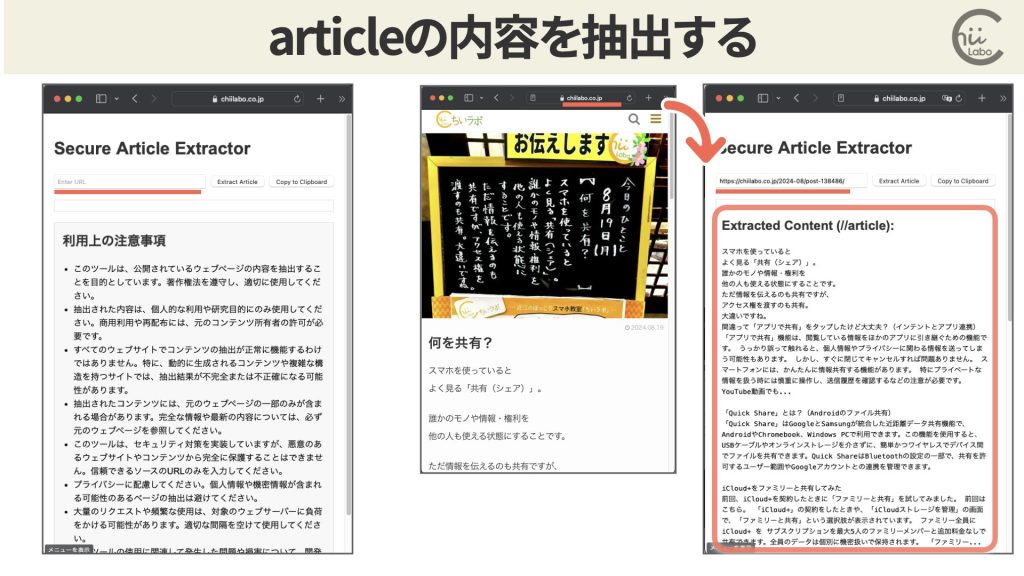
ツールの使い方を具体的に説明しましょう。
- まず、ウェブブラウザでこのツールのページを開きます。
- 画面上部の「Enter URL」欄に読みたい記事のURLを入力します。
- 「Extract Article」ボタンを押します。
- 画面の下半分に記事の内容が表示されます。
- 記事をコピーしたい場合は、「Copy to Clipboard」ボタンを押します。
- コピーが成功すると、画面の右下に「Article content copied to clipboard!」というメッセージが表示されます。
このツールを使えば、ウェブページ上の記事から必要な部分だけを簡単に取り出すことができます。
2. 最初の一歩:基本的な抽出機能の作成
まず始めに、ウェブページのURLを入力すると、そのページの主要な部分を取り出す機能を作りました。
ページの中から「article」というタグで囲まれた部分を探し出し、その中身を表示します。
- ユーザーが入力したURLからウェブページのHTMLを取得します。
- 取得したHTMLから、DOMDocumentとXPathを使用して’article’タグを探索します。
- ‘article’タグが見つかった場合、その内容をテキストとして抽出します。
- ‘article’タグが見つからない場合、’body’タグの内容を抽出します。
- 抽出されたテキストをウェブページ上に表示します。
- ユーザーは「Copy to Clipboard」ボタンを使って、抽出されたテキストをクリップボードにコピーできます。
- エラーが発生した場合(URLが無効、ページが見つからないなど)、適切なエラーメッセージを表示します。
<?php
function extractArticleText($url) {
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36');
$html = curl_exec($ch);
if ($html === false) {
return "Error: " . curl_error($ch);
}
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
if ($httpCode != 200) {
return "Error: HTTP status code: $httpCode";
}
curl_close($ch);
libxml_use_internal_errors(true);
$doc = new DOMDocument();
$doc->loadHTML($html);
$xpath = new DOMXPath($doc);
$article = $xpath->query('//article');
if ($article->length > 0) {
return $article->item(0)->textContent;
} else {
$body = $xpath->query('//body');
if ($body->length > 0) {
return $body->item(0)->textContent;
} else {
return "No content found on this page.";
}
}
}
$result = '';
$url = '';
$error = '';
if ($_SERVER['REQUEST_METHOD'] === 'POST' || isset($_GET['url'])) {
$url = $_POST['url'] ?? $_GET['url'] ?? '';
if ($url) {
$result = extractArticleText($url);
if (strpos($result, 'Error:') === 0) {
$error = $result;
$result = '';
}
} else {
$error = 'No URL provided';
}
if (!empty($_SERVER['HTTP_X_REQUESTED_WITH']) && strtolower($_SERVER['HTTP_X_REQUESTED_WITH']) == 'xmlhttprequest') {
header('Content-Type: application/json');
echo json_encode(['result' => $result, 'error' => $error]);
exit;
}
}
?>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Article Extractor</title>
<script src="https://code.jquery.com/jquery-3.6.0.min.js"></script>
<script>
$(document).ready(function() {
$('#extractForm').submit(function(e) {
e.preventDefault();
$('#result').html('<p class="loading">Loading...</p>');
$('#copyButton').hide();
$.ajax({
type: 'POST',
url: window.location.href,
data: $(this).serialize(),
dataType: 'json',
success: function(response) {
console.log('Response:', response); // デバッグ用
if (response.error) {
$('#result').html('<p class="error">' + response.error + '</p>');
$('#copyButton').hide();
} else if (response.result) {
$('#result').html('<h2>Extracted Content:</h2><pre>' + response.result + '</pre>');
$('#copyButton').show();
} else {
$('#result').html('<p>No content extracted.</p>');
$('#copyButton').hide();
}
},
error: function(jqXHR, textStatus, errorThrown) {
console.error('AJAX Error:', textStatus, errorThrown); // デバッグ用
$('#result').html('<p class="error">An error occurred while processing your request. Please check the console for details.</p>');
$('#copyButton').hide();
}
});
});
$('#copyButton').click(function() {
var content = $('#result pre').text();
copyToClipboard(content);
alert('Article content copied to clipboard!');
});
function copyToClipboard(text) {
var textarea = document.createElement("textarea");
textarea.textContent = text;
textarea.style.position = "fixed";
document.body.appendChild(textarea);
textarea.select();
try {
return document.execCommand("copy");
} catch (ex) {
console.warn("Copy to clipboard failed.", ex);
return false;
} finally {
document.body.removeChild(textarea);
}
}
// Initial button visibility
if ($('#result pre').length > 0) {
$('#copyButton').show();
} else {
$('#copyButton').hide();
}
});
</script>
<style>
body { font-family: Arial, sans-serif; line-height: 1.6; padding: 20px; max-width: 800px; margin: 0 auto; }
h1 { color: #333; }
form { margin-bottom: 20px; }
input[type="url"] { width: 70%; padding: 5px; }
button { padding: 5px 10px; cursor: pointer; }
#result { margin-top: 20px; border: 1px solid #ddd; padding: 10px; }
pre { white-space: pre-wrap; word-wrap: break-word; }
.error { color: red; }
.loading { color: #666; }
#copyButton { margin-top: 10px; }
</style>
</head>
<body>
<h1>Article Extractor</h1>
<form id="extractForm" method="post">
<input type="url" name="url" required placeholder="Enter URL" value="<?php echo htmlspecialchars($url); ?>">
<button type="submit">Extract Article</button>
</form>
<div id="result">
<?php
if ($error) {
echo '<p class="error">' . htmlspecialchars($error) . '</p>';
} elseif ($result) {
echo '<h2>Extracted Content:</h2><pre>' . htmlspecialchars($result) . '</pre>';
}
?>
</div>
<button id="copyButton" style="display: <?php echo $result ? 'block' : 'none'; ?>;">Copy to Clipboard</button>
</body>
</html>この PHPコードを(たとえば、index.phpという名前で)PHPが動作するウェブサーバー内に保存するとアクセスできるようになります。
3. 改善への道:より賢い抽出方法の模索
しかし、すぐに問題が発生しました。
全てのウェブページが同じ構造になっているわけではないのです。
そこで、もっと賢い方法でページ内容を見つけ出す必要がありました。
「Readability」というアルゴリズムを参考にして、新しい抽出方法を考えました。
この方法では、ページの構造を細かく分析し、「最も記事らしい部分」を特定します。
例えば、
長い文章が続いている部分や、特定の言葉(「content」や「article」など)が含まれている部分を重視します。
また、記事以外の部分(ヘッダーやフッター、広告など)を取り除く機能も追加しました。
例えば、
「header」や「footer」、「ad」といった言葉が含まれる部分は除外するようにしました。
<?php
function extractArticleText($url) {
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36');
$html = curl_exec($ch);
if ($html === false) {
return ["error" => "Error: " . curl_error($ch)];
}
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
if ($httpCode != 200) {
return ["error" => "Error: HTTP status code: $httpCode"];
}
curl_close($ch);
libxml_use_internal_errors(true);
$doc = new DOMDocument();
@$doc->loadHTML(mb_convert_encoding($html, 'HTML-ENTITIES', 'UTF-8'));
$xpath = new DOMXPath($doc);
// Remove unwanted elements
removeUnwantedElements($xpath);
// Extract content
$content = extractContent($xpath);
if ($content) {
return ["content" => $content, "algorithm" => "Refined Extraction"];
}
return ["error" => "No relevant content found on this page."];
}
function removeUnwantedElements($xpath) {
$unwantedSelectors = [
'//header', '//footer', '//nav',
'//aside', '//sidebar',
'//div[contains(@class, "sidebar")]',
'//div[contains(@class, "menu")]',
'//div[contains(@class, "nav")]',
'//div[contains(@class, "header")]',
'//div[contains(@class, "footer")]',
'//script', '//style', '//iframe',
'//div[contains(@class, "comment")]',
'//div[contains(@id, "comment")]',
'//div[contains(@class, "advertisement")]',
'//div[contains(@class, "ad")]'
];
foreach ($unwantedSelectors as $selector) {
$unwantedNodes = $xpath->query($selector);
foreach ($unwantedNodes as $node) {
$node->parentNode->removeChild($node);
}
}
}
function extractContent($xpath) {
$contentSelectors = [
'//article',
'//div[contains(@class, "post-content")]',
'//div[contains(@class, "entry-content")]',
'//div[contains(@class, "article-content")]',
'//div[contains(@class, "content")]',
'//main'
];
foreach ($contentSelectors as $selector) {
$nodes = $xpath->query($selector);
if ($nodes->length > 0) {
$content = '';
foreach ($nodes as $node) {
$content .= extractCleanText($node);
}
if (strlen($content) > 100) { // Ensure we have substantial content
return $content;
}
}
}
// If no content found with specific selectors, try a more general approach
$bodyContent = $xpath->query('//body')[0];
return extractCleanText($bodyContent);
}
function extractCleanText($node) {
$text = '';
foreach ($node->childNodes as $child) {
if ($child->nodeType === XML_TEXT_NODE) {
$text .= trim($child->nodeValue) . "\n";
} elseif ($child->nodeType === XML_ELEMENT_NODE && !in_array(strtolower($child->nodeName), ['script', 'style'])) {
$text .= extractCleanText($child);
}
}
return $text;
}
$result = '';
$algorithm = '';
$url = '';
$error = '';
if ($_SERVER['REQUEST_METHOD'] === 'POST' || isset($_GET['url'])) {
$url = $_POST['url'] ?? $_GET['url'] ?? '';
if ($url) {
$extraction_result = extractArticleText($url);
if (isset($extraction_result['error'])) {
$error = $extraction_result['error'];
} else {
$result = $extraction_result['content'];
$algorithm = $extraction_result['algorithm'];
}
} else {
$error = 'No URL provided';
}
if (!empty($_SERVER['HTTP_X_REQUESTED_WITH']) && strtolower($_SERVER['HTTP_X_REQUESTED_WITH']) == 'xmlhttprequest') {
header('Content-Type: application/json');
echo json_encode(['result' => $result, 'algorithm' => $algorithm, 'error' => $error]);
exit;
}
}
?>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Refined Article Extractor</title>
<script src="https://code.jquery.com/jquery-3.6.0.min.js"></script>
<script>
$(document).ready(function() {
$('#extractForm').submit(function(e) {
e.preventDefault();
$('#result').html('<p class="loading">Loading...</p>');
$.ajax({
type: 'POST',
url: window.location.href,
data: $(this).serialize(),
dataType: 'json',
success: function(response) {
console.log('Response:', response); // For debugging
if (response.error) {
$('#result').html('<p class="error">' + response.error + '</p>');
} else if (response.result) {
var content = '<h2>Extracted Content (' + response.algorithm + '):</h2><pre>' + response.result + '</pre>';
$('#result').html(content);
copyToClipboard(response.result);
setTimeout(function() {
alert('Article content extracted and copied to clipboard!');
}, 100);
} else {
$('#result').html('<p>No content extracted.</p>');
}
},
error: function(jqXHR, textStatus, errorThrown) {
console.error('AJAX Error:', textStatus, errorThrown); // For debugging
$('#result').html('<p class="error">An error occurred while processing your request. Please check the console for details.</p>');
}
});
});
$('#copyButton').click(function() {
var content = $('#result pre').text();
if (content) {
copyToClipboard(content);
alert('Article content copied to clipboard!');
} else {
alert('No content to copy. Please extract an article first.');
}
});
function copyToClipboard(text) {
var textarea = document.createElement("textarea");
textarea.textContent = text;
textarea.style.position = "fixed";
document.body.appendChild(textarea);
textarea.select();
try {
return document.execCommand("copy");
} catch (ex) {
console.warn("Copy to clipboard failed.", ex);
return false;
} finally {
document.body.removeChild(textarea);
}
}
});
</script>
<style>
body { font-family: Arial, sans-serif; line-height: 1.6; padding: 20px; max-width: 800px; margin: 0 auto; }
h1 { color: #333; }
form { margin-bottom: 20px; display: flex; gap: 10px; }
input[type="url"] { flex-grow: 1; padding: 5px; }
button { padding: 5px 10px; cursor: pointer; white-space: nowrap; }
#result { margin-top: 20px; border: 1px solid #ddd; padding: 10px; }
pre { white-space: pre-wrap; word-wrap: break-word; }
.error { color: red; }
.loading { color: #666; }
</style>
</head>
<body>
<h1>Refined Article Extractor</h1>
<form id="extractForm" method="post">
<input type="url" name="url" required placeholder="Enter URL" value="<?php echo htmlspecialchars($url); ?>">
<button type="submit">Extract Article</button>
<button type="button" id="copyButton">Copy to Clipboard</button>
</form>
<div id="result">
<?php
if ($error) {
echo '<p class="error">' . htmlspecialchars($error) . '</p>';
} elseif ($result) {
echo '<h2>Extracted Content (' . htmlspecialchars($algorithm) . '):</h2><pre>' . htmlspecialchars($result) . '</pre>';
}
?>
</div>
</body>
</html>4. セキュリティ対策
最後にセキュリティ対策をしました。
インターネット上には様々な脅威が存在するため、アプリケーションをより安全に保つための対策を講じます。
- 入力のサニタイズ:
悪意のある人が、有害なコードを含むURLを入力する可能性があるため、filter_input()関数を使用して、URLの入力をサニタイズしています。 - CSRF対策:
他のウェブサイトが、ユーザーに気づかれずにこのアプリケーションにリクエストを送る可能性があるため、セッションベースのCSRFトークンを生成し、フォーム送信時に検証しています。 - XSS対策:
悪意のある人が、ウェブページに有害なスクリプトを埋め込む可能性があるため、出力時にhtmlspecialchars()を使用して、特殊文字をエスケープしています。
JavaScript側でも、jQueryのtext()メソッドを使用して安全にコンテンツを挿入しています。
HTMLエンティティのエンコード、危険なJavaScriptイベントハンドラの削除、データURIの削除、HTMLコメントの削除を行います。 - レート制限:
同一IPアドレスごとに1分あたり10回までのリクエストしか受け付けないようにしました。
<?php
// セッションを開始し、CSRF対策のためのトークンを生成
session_start();
if (empty($_SESSION['csrf_token'])) {
$_SESSION['csrf_token'] = bin2hex(random_bytes(32));
}
// レート制限の設定
define('MAX_REQUESTS', 10); // 制限時間内の最大リクエスト数
define('TIME_WINDOW', 60); // 制限時間(秒)
// IPアドレスごとのリクエスト制限をチェック
function checkRateLimit() {
$clientIP = $_SERVER['REMOTE_ADDR'];
$currentTime = time();
if (!isset($_SESSION['rate_limit'][$clientIP])) {
$_SESSION['rate_limit'][$clientIP] = [
'count' => 1,
'last_request_time' => $currentTime
];
return true;
}
$lastRequestTime = $_SESSION['rate_limit'][$clientIP]['last_request_time'];
$count = $_SESSION['rate_limit'][$clientIP]['count'];
if ($currentTime - $lastRequestTime > TIME_WINDOW) {
// 制限時間が経過したらカウントをリセット
$_SESSION['rate_limit'][$clientIP] = [
'count' => 1,
'last_request_time' => $currentTime
];
return true;
}
if ($count >= MAX_REQUESTS) {
return false; // レート制限超過
}
// リクエストカウントを増やす
$_SESSION['rate_limit'][$clientIP]['count']++;
$_SESSION['rate_limit'][$clientIP]['last_request_time'] = $currentTime;
return true;
}
function extractArticleText($url) {
// URLのバリデーション
if (!filter_var($url, FILTER_VALIDATE_URL)) {
return ["error" => "Invalid URL format"];
}
// 制限されたドメインへのアクセスを拒否
$restrictedDomains = ['example.com', 'restricted.com']; // 制限するドメインのリスト
$parsedUrl = parse_url($url);
if (in_array($parsedUrl['host'], $restrictedDomains)) {
return ["error" => "Access to this domain is restricted"];
}
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36');
curl_setopt($ch, CURLOPT_TIMEOUT, 10); // タイムアウトを設定
$html = curl_exec($ch);
if ($html === false) {
return ["error" => "Error: " . curl_error($ch)];
}
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
if ($httpCode != 200) {
return ["error" => "Error: HTTP status code: $httpCode"];
}
curl_close($ch);
libxml_use_internal_errors(true);
$doc = new DOMDocument();
@$doc->loadHTML(mb_convert_encoding($html, 'HTML-ENTITIES', 'UTF-8'));
$xpath = new DOMXPath($doc);
removeUnwantedElements($xpath);
$result = extractContent($xpath);
if ($result["content"]) {
return $result;
}
return ["error" => "No relevant content found on this page."];
}
function removeUnwantedElements($xpath) {
$unwantedSelectors = [
'//header', '//footer', '//nav',
'//aside', '//sidebar',
'//div[contains(@class, "sidebar")]',
'//div[contains(@class, "menu")]',
'//div[contains(@class, "nav")]',
'//div[contains(@class, "header")]',
'//div[contains(@class, "footer")]',
'//script', '//style', '//iframe',
'//div[contains(@class, "comment")]',
'//div[contains(@id, "comment")]',
'//div[contains(@class, "widget")]',
'//div[contains(@class, "advertisement")]',
'//div[contains(@class, "ad")]'
];
foreach ($unwantedSelectors as $selector) {
$unwantedNodes = $xpath->query($selector);
foreach ($unwantedNodes as $node) {
$node->parentNode->removeChild($node);
}
}
}
function extractContent($xpath) {
$contentSelectors = [
'//article',
'//div[contains(@class, "post-content")]',
'//div[contains(@class, "entry-content")]',
'//div[contains(@class, "article-content")]',
'//div[contains(@class, "content")]',
'//div[contains(@id, "threadMainContainer")]',
'//div[contains(@id, "threadMainContent")]',
'//main'
];
foreach ($contentSelectors as $selector) {
$nodes = $xpath->query($selector);
if ($nodes->length > 0) {
$content = '';
foreach ($nodes as $node) {
$content .= extractCleanText($node);
}
if (strlen($content) > 100) {
return ["content" => sanitizeContent($content), "algorithm" => $selector];
}
}
}
$bodyContent = $xpath->query('//body')[0];
return ["content" => extractCleanText($bodyContent), "algorithm" => '//body'];
}
function extractCleanText($node) {
$text = '';
foreach ($node->childNodes as $child) {
if ($child->nodeType === XML_TEXT_NODE) {
$text .= trim($child->nodeValue) . "\n";
} elseif ($child->nodeType === XML_ELEMENT_NODE && !in_array(strtolower($child->nodeName), ['script', 'style'])) {
$text .= extractCleanText($child);
}
}
return $text;
}
function sanitizeContent($content) {
// HTMLエンティティをエンコード
$content = htmlspecialchars($content, ENT_QUOTES | ENT_HTML5, 'UTF-8');
// 潜在的に危険なJavaScriptイベントハンドラを削除
$content = preg_replace('/on\w+="[^"]*"/i', '', $content);
// データURIを削除
$content = preg_replace('/data:\s*[^;]*;base64,/i', '', $content);
// コメントを削除
$content = preg_replace('/<!--(.|\s)*?-->/', '', $content);
return $content;
}
$result = '';
$algorithm = '';
$url = '';
$error = '';
// CSRF対策
if ($_SERVER['REQUEST_METHOD'] === 'POST') {
if (!isset($_POST['csrf_token']) || $_POST['csrf_token'] !== $_SESSION['csrf_token']) {
die('CSRF token validation failed');
}
}
if ($_SERVER['REQUEST_METHOD'] === 'POST' || isset($_GET['url'])) {
// レート制限チェック
if (!checkRateLimit()) {
$error = 'Rate limit exceeded. Please try again later.';
} else {
$url = filter_input(INPUT_POST, 'url', FILTER_SANITIZE_URL) ?? filter_input(INPUT_GET, 'url', FILTER_SANITIZE_URL) ?? '';
if ($url) {
$extraction_result = extractArticleText($url);
if (isset($extraction_result['error'])) {
$error = $extraction_result['error'];
} else {
$result = $extraction_result['content'];
$algorithm = $extraction_result['algorithm'];
}
} else {
$error = 'No URL provided';
}
}
if (!empty($_SERVER['HTTP_X_REQUESTED_WITH']) && strtolower($_SERVER['HTTP_X_REQUESTED_WITH']) == 'xmlhttprequest') {
header('Content-Type: application/json');
echo json_encode(['result' => $result, 'algorithm' => $algorithm, 'error' => $error]);
exit;
}
}
?>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Enhanced Secure Article Extractor</title>
<script src="https://code.jquery.com/jquery-3.6.0.min.js"></script>
<script>
$(document).ready(function() {
$('#extractForm').submit(function(e) {
e.preventDefault();
$('#result').html('<p class="loading">Loading...</p>');
$.ajax({
type: 'POST',
url: window.location.href,
data: $(this).serialize(),
dataType: 'json',
success: function(response) {
if (response.error) {
$('#result').html('<p class="error">' + $('<div>').text(response.error).html() + '</p>');
} else if (response.result) {
var content = '<h2>Extracted Content (' + $('<div>').text(response.algorithm).html() + '):</h2><pre>' + $('<div>').text(response.result).html() + '</pre>';
$('#result').html(content);
copyToClipboard(response.result);
setTimeout(function() {
alert('Article content extracted and copied to clipboard!');
}, 100);
} else {
$('#result').html('<p>No content extracted.</p>');
}
},
error: function(jqXHR, textStatus, errorThrown) {
$('#result').html('<p class="error">An error occurred while processing your request.</p>');
}
});
});
$('#copyButton').click(function() {
var content = $('#result pre').text();
if (content) {
copyToClipboard(content);
alert('Article content copied to clipboard!');
} else {
alert('No content to copy. Please extract an article first.');
}
});
function copyToClipboard(text) {
var textarea = document.createElement("textarea");
textarea.textContent = text;
textarea.style.position = "fixed";
document.body.appendChild(textarea);
textarea.select();
try {
return document.execCommand("copy");
} catch (ex) {
console.warn("Copy to clipboard failed.");
return false;
} finally {
document.body.removeChild(textarea);
}
}
});
</script>
<style>
body { font-family: Arial, sans-serif; line-height: 1.6; padding: 20px; max-width: 800px; margin: 0 auto; }
h1, h2 { color: #333; }
form { margin-bottom: 20px; display: flex; gap: 10px; }
input[type="url"] { flex-grow: 1; padding: 5px; }
button { padding: 5px 10px; cursor: pointer; white-space: nowrap; }
#result { margin-top: 20px; border: 1px solid #ddd; padding: 10px; }
pre { white-space: pre-wrap; word-wrap: break-word; }
.error { color: red; }
.loading { color: #666; }
.guidelines { background-color: #f8f8f8; border: 1px solid #ddd; padding: 15px; margin-top: 20px; }
.guidelines h2 { margin-top: 0; }
.guidelines ul { padding-left: 20px; }
</style>
</head>
<body>
<h1>Secure Article Extractor</h1>
<form id="extractForm" method="post">
<input type="url" name="url" required placeholder="Enter URL" value="<?php echo htmlspecialchars($url); ?>">
<input type="hidden" name="csrf_token" value="<?php echo htmlspecialchars($_SESSION['csrf_token']); ?>">
<button type="submit">Extract Article</button>
<button type="button" id="copyButton">Copy to Clipboard</button>
</form>
<div id="result">
<?php
if ($error) {
echo '<p class="error">' . htmlspecialchars($error) . '</p>';
} elseif ($result) {
echo '<h2>Extracted Content (' . htmlspecialchars($algorithm) . '):</h2><pre>' . $result . '</pre>';
}
?>
</div>
<div class="guidelines">
<h2>利用上の注意事項</h2>
<ul>
<li>このツールは、公開されているウェブページの内容を抽出することを目的としています。著作権法を遵守し、適切に使用してください。</li>
<li>抽出された内容は、個人的な利用や研究目的にのみ使用してください。商用利用や再配布には、元のコンテンツ所有者の許可が必要です。</li>
<li>すべてのウェブサイトでコンテンツの抽出が正常に機能するわけではありません。特に、動的に生成されるコンテンツや複雑な構造を持つサイトでは、抽出結果が不完全または不正確になる可能性があります。</li>
<li>抽出されたコンテンツには、元のウェブページの一部のみが含まれる場合があります。完全な情報や最新の内容については、必ず元のウェブページを参照してください。</li>
<li>このツールは、セキュリティ対策を実装していますが、悪意のあるウェブサイトやコンテンツから完全に保護することはできません。信頼できるソースのURLのみを入力してください。</li>
<li>プライバシーに配慮してください。個人情報や機密情報が含まれる可能性のあるページの抽出は避けてください。</li>
<li>大量のリクエストや頻繁な使用は、対象のウェブサーバーに負荷をかける可能性があります。適切な間隔を空けて使用してください。</li>
<li>このツールの使用に関連して発生した問題や損害について、開発者は一切の責任を負いません。自己責任でご利用ください。</li>
</ul>
</div>
</body>
</html>PHPが動作するサイトなら、このコード単体で動くはずです。
こちらもどうぞ。
![[JavaScript]全選択で記事部分だけになるようにした](data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxOTIwIiBoZWlnaHQ9IjEwODAiIHZpZXdCb3g9IjAgMCAxOTIwIDEwODAiPjxyZWN0IHdpZHRoPSIxMDAlIiBoZWlnaHQ9IjEwMCUiIGZpbGw9IiNmZmZmZmYiLz48L3N2Zz4=)

![[JavaScript]全選択で記事部分だけになるようにした](https://chiilabo.com/wp-content/uploads/2024/05/image-13-57-1024x576.jpg)
[JavaScript]全選択で記事部分だけになるようにした
自分のサイト内の記事全体を選択しやすいように、スクリプトを作りました。window.getSelection()テーマのjavascript.jsに以下のコードを追加しました。document.addEventListener('keydown', function(event) { if ((event.ctrlKey || event.metaKey) && event.key === 'a') { event.preventDefault(); const articl...
chiilabo.com
QRコード生成APIをGoogleからqrserver.comに変更した
ついに GoogleAPIsのQRコード生成APIが終了していたので、QR code generator(goqr.me)のAPIに変更しました。変更前: ' . $url変更後: ' . urlencode($url)前提: $url = get_the_permalink();URLをURLエンコードするのがポイントです。QRコードが表示されていない?このサイトの記事を印刷すると、その記事のQRコードが印刷されるように設定しています。ところが、久しぶりに印刷されたものを確...
chiilabo.com
![[Mac] PC内で検証用ウェブサーバを動かす【php -S】](https://chiilabo.com/wp-content/uploads/2023/06/image-4-3-1024x576.jpg)
[Mac] PC内で検証用ウェブサーバを動かす【php -S】
phina.js のプログラムをローカルで検証するために、ウェブサーバを立ち上げることにしました。ブラウザでHTMLファイルを開いてもサイトと違うただのファイルとして html を開いた場合(たとえば「file:///Users/user/html/index.html」など)、JavaScriptから相対アドレスでほかのローカルファイルを読み込んだりはできません。JavaScriptのセキュリティ上の制限で、ローカルファイルにはアクセスできないからです。そのため、サイトデー...
chiilabo.com

Chromeにサイト内検索の「ショートカット」を登録した
Chromeの設定でサイト内検索のショートカットを登録すると、どのページからでもすぐに検索できて便利です。 設定の「検索エンジン」から「サイト内検索」を追加して、名前とショートカット、URLを登録します。 URLは実際にサイト内検索をしたときのURLを使い、検索語句の部分を「%s」に置き換えます。サイト内検索をもっと効率的に使いたい自分のブログ記事を探すのにサイト内検索をよく使います。そこで、Chromeの設定で ちいラボ の「検索ショートカット」として「ch」を登録しました...
chiilabo.com
QRコードを読み込むと、関連記事を確認できます。
![[PHP]ウェブページの内容を抽出するオンラインツールを作るには?](https://api.qrserver.com/v1/create-qr-code/?data=?size=200x200&data=https%3A%2F%2Fchiilabo.com%2F2024-08%2Fphp-custom-tool-web-content-extraction%2F)
![[WordPress]画像キャプションをalt属性を自動設定するカスタムスクリプト(functions.php)](https://chiilabo.com/wp-content/uploads/2024/07/image-28-32-1024x576.jpg)
![[Excel]個人用マクロブックがロックされないように「読み取り専用」にするマクロのメリット・デメリット(ChangeFileAccess, xlReadOnly)](https://chiilabo.com/wp-content/uploads/2024/02/image-24-1024x576.jpg)