
- ふと、フリーレンの「勇者ヒンメルならそうしたってことだよ」という台詞が、生成AIの仕組みにちょっと似ているな、と思いました。
- AIの特徴の一つは、無限に学習した記憶から取り出すことです。
- これは、誰と判別できずとも、過去の誰かの行動パターンを模倣していることに近いです。
たまたまかもしれないけど、フリーレンも生成AIも同じ2023年にヒットしたのは面白いよね。
1. 生成AIの学習プロセス
AIが大量のデータから学習するプロセスは、フリーレンのようなエルフが1000年以上の長い寿命を通じて蓄積する経験や知識と似ているのかもしれません。
生成AI、特にGPT(Generative Pre-trained Transformer)系のモデルは、膨大なテキストデータを事前に学習しています。
パターンを把握するために、小説、ニュース記事、ブログ投稿、科学論文など、さまざまなジャンルのテキストを読み込みます。
この大量のデータから学習して、AIは与えられたプロンプトの「続き」を応答します。
この方法、ちょっとやそっとの学習量では、荒唐無稽な応答ばかりだったのですが、ある一定の段階から急に意味のある、文脈に沿った応答を生成できるようになりました。
1.1. 膨大な記憶と想起
フリーレンには、目の前の状況から過去を振り返るシーンが多いです。
「勇者ヒンメルならそうしたってことだよ」というセリフは、その代表(?)かもしれません。

これは、エルフの持つ長い時間感覚を印象付けるものですが、プロンプトにも似ています。
記憶を想起する鍵は、常に目の前の状況なのです。
生成AIは、現在の入力(プロンプト)に対して、応答を生成しています。
しかし、これは学習したデータを確率的に「重ね合わせ」て、浮かび上がったものです。
生成AIは、膨大な記憶の中から勇者ヒンメルのような「誰か(複数)」の面影を、「思い出して」いると言えます。
2. 記憶の中から誰かと判別できずとも
つまり、生成されたデータには、そのもとになった人々がいるわけです。
それが、いろいろ重なり合って、具体的な誰かとは判別できないとしても。
しかし、特に「画像生成」の分野では、これが大きな問題になります。
生成されたイラストの画風が既存の画家を真似たものだったり、生成された写真が実在の人物に瓜二つだったり。
2.1. テキストと画像の違い
一方、文字記号で構成される「文章」や「コード」の分野では、そこまで元の誰かは、見えてきません。
これは、言語と画像の違いによると思います。
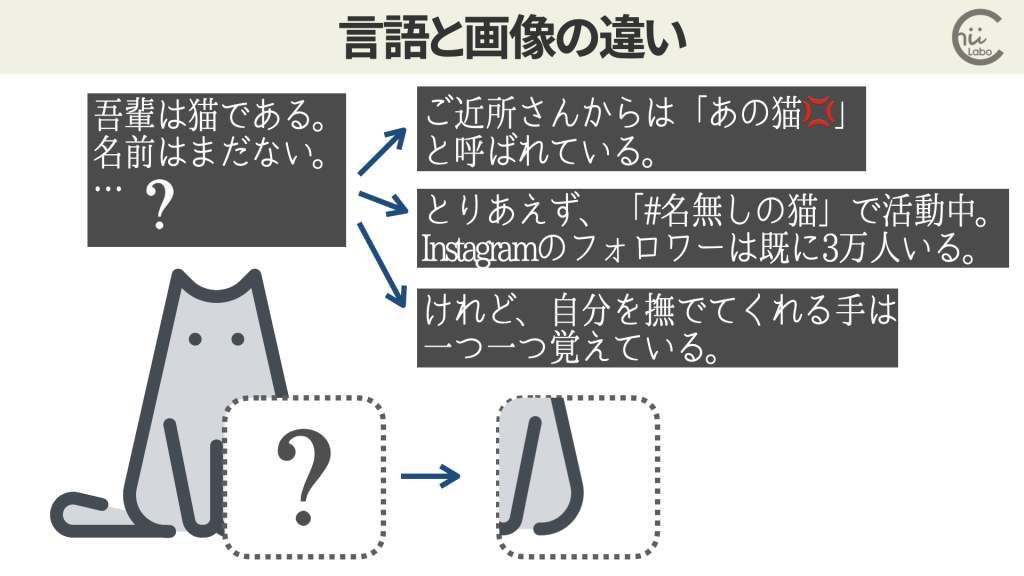
言語(あるいはテキストデータ)には、かなり自由に結合・分離できる性質(構成性:Compositionality)があります。
ある文章の続きには、いろんなパターン・可能性がありえます。
一方、画像の場合は、途中まで出来上がると、残りの部分はほぼ決まってきます。
文脈が決まってくるにつれ、使える学習データの範囲は徐々に狭くなります。
既存のものが色濃く出やすいのです。


![[ChatGPT] チャットのアーカイブが「Unable to load conversation 〜」で開けない(言語設定を「Auto-detect」にする)](https://chiilabo.com/wp-content/uploads/2024/02/image-30-13-1024x576.jpg)
